Download our e-book of Introduction To Python
Related Blog
Matplotlib - Subplot2grid() FunctionDiscuss Microsoft Cognitive ToolkitMatplotlib - Working with ImagesMatplotlib - PyLab moduleMatplotlib - Working With TextMatplotlib - Setting Ticks and Tick LabelsCNTK - Creating First Neural NetworkMatplotlib - MultiplotsMatplotlib - Quiver PlotPython - Chunks and Chinks View More
Top Discussion
How can I write Python code to change a date string from "mm/dd/yy hh: mm" format to "YYYY-MM-DD HH: mm" format? Which sorting technique is used by sort() and sorted() functions of python? How to use Enum in python? Can you please help me with this error? I was just selecting some random columns from the diabetes dataset of sklearn. Decision tree is a classification algo...How can it be applied to load diabetes dataset which has DV continuous Objects in Python are mutable or immutable? How can unclassified data in a dataset be effectively managed when utilizing a decision tree-based classification model in Python? How to leave/exit/deactivate a Python virtualenvironment Join Discussion
Top Courses
Webinars
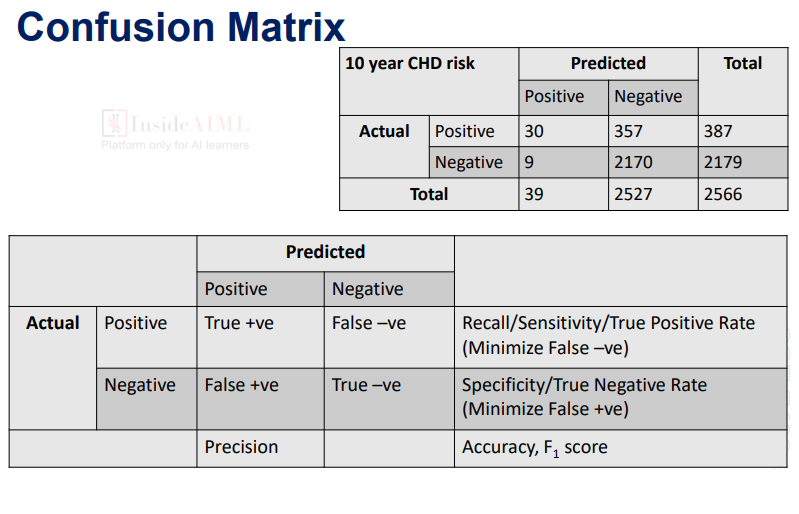
What is Confusion Matrix?

Sulochana Kamshetty
2 years ago
Confusion…Confusion. Confusion..

Table of Content
- What is Confusion Matrix:-
- What is Recall/Sensitivity/true Positive Rate ?
- What is Specificity/true Negative Rate
- What is Precision?
- What is Accuracy/F1 Score?
- Conclusion
Confusion is truly confusion…… When comes to the point of understanding, the concept, but let’s aim to clear the concept by taking few examples, and makes this confusion clear by the end of this concept.
Once the basic steps of working with any project like, preprocessing steps, data cleansing and wrangling of the data. We need to further proceed with measuring the effectiveness of our model, but how do we do that, there comes the point of working with the confusion matrix, which will helps us giving the better output then estimated one.
Covering important questions of confusion matrix into consideration. Like..!!
1. What is confusion matrix?
2. How to calculate confusion matrix for a 2-class classification problem?
3. What is recall?
4. What is precision?
5. What is accuracy?
What is Confusion Matrix:-
Confusion matrix is made special type of contingency table, in which it contains two dimensions each with combination of dimension and class. Where class is a variable in the this table with created “actual” and “predicted” set of identical class. Which is the performance measurement for machine learning classification,& also known as Error matrix.
Supervised learning allows the table layout, that allows the visualization of the performance of the algorithm, but in unsupervised learning its usually called a matching matrix..
Case Study:-
Its quite common we receive mails which are categorized under “promotion”, “social” and “Primary”. Now, the situation comes where we know that one of our mail is been wrongly misplaced in spam, which is not actually a spam mail, and there are few mails which are non spam, and are “actually spam mails”. So how to over come this kind of getting the clarification problems, there comes with confusion matric which gives the final clarity among these doubts we have..
There are 4 situations, where this classification problem arise..
- Actual true also predicted true called (true Positive).
- Actual false also predicted false called (true Negative).
- Actual not true but predicted true called (false Positive).
- Actual true but predicted false called(false Negative).
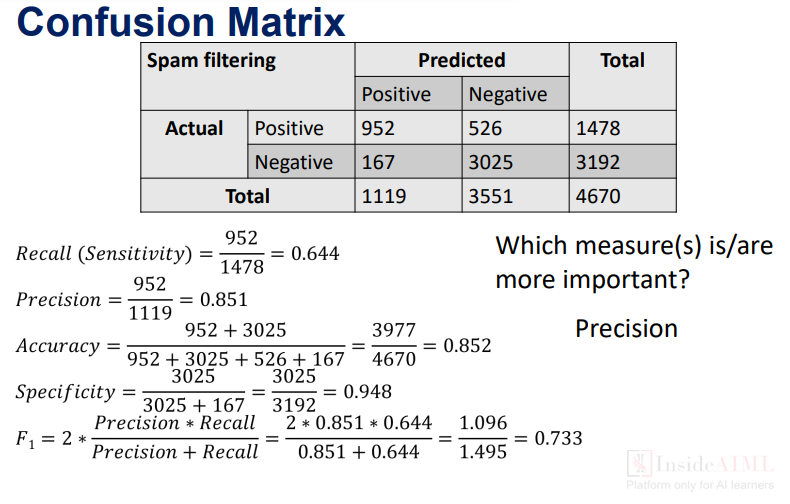
Since that we got familiar with (TP,TN,FP & FN). Now lets continue with the same spam case study, with the help of this below table.
Note:- “Actual ”and “Predicted ”are two identical class. which can also be denoted as “0” & “1”.
From the above table, lets understand what does these technical terms are used in this concept.
- The spam which are actual positive, and predicted positive are 952 and
- The spam which are actual negative and are predicted positive are 167,
- The spam which are actual positive but are predicted negative are 526,
- The spam which are actual negative also predicted negative are 3025.
Once the total sum of the classifications, are done the next step is to know about important concepts of confusion matrix, which are called Recall/sensitivity/true positive rate(minimize false -ve), specificity/true negative rate(minimize false +ve), Accuracy, or F1 score,and Precision.
What is Recall/Sensitivity/true Positive Rate ?
Recall is defined as the ratio of actual positive with total predicted positives. which gives only the value of total actual values.
But when do we use this?
It is only used when we are looking for only “positive response” out of the total situation.
With the help of above picture, it gives the idea how the recall values are considered for the calculation part.
where:-
R= TP/ TP+FN where the total positive spam are 952/952+526= 0.644
“The good recall score ideally will be 1, if both the numerator and denominator are equal”.
What is Specificity/true Negative Rate (Minimize false + ve)
Specificity is defined as the ratio of considered actual negative but predicted positive values, which is also the reverse order of recall rate.
This works with the condition, where the spam mails are true negative, but are marked or identified as positive.
It helps us to determine the only/total calculated negative values.
R= TN /TN +FP where the total negative spam are 3025/3025+165 = 0.852
What is Precision?
It is defined as the ratio of actual positive values, with the total positive values includes the actual negative values too.
R = TP/TP+TN where the total positive values are 952/1119 = 0.851
This also defines, where FP is zero. As Fp increases the value of denominator, becomes greater than the numerator, and precision value decreases (which we don’t want).
Note:-
Precision should ideally be 1 (high) for a good classifier.
Precision becomes 1, only when the numerator and denominator are equal.
What is Accuracy/F1 Score?
F1-score is a metric which takes into account both “precision and recall ”and is defined as follows:
Total Accuracy [which is = (true Positive + true Negative) / Total Population].
Therefore:- 952+3025/952+3025+526+167 = 3977/4670=0.852
Note:-
Among all the metric, Accuracy is also the most important one, since that it helps in predicting if a spam is “actual positive”. So in this case, we can probably tolerate false Positives but not false Negatives.
Conclusion:-
In this content, we learned how a classification model could be effectively evaluated, especially in situations where looking at standalone accuracy is not enough. We understood concepts like “TP, TN, FP, FN, Precision, Recall, Confusion matrix”, with examples and explanations.
Hope this made clear about the concepts we used today…for more such interesting content or to get more expertise grab the knowledge from.
Like the Blog, then Share it with your friends and colleagues to make this AI community stronger.
To learn more about nuances of Artificial Intelligence, Python Programming, Deep Learning, Data Science and Machine Learning, visit our insideAIML blog page.
Keep Learning. Keep Growing.
Thank you..